TLDR; We had moved our database onto the same machine as our software a few months earlier, removing all replication in the process and never re-configuring it. Then our server proceeded to brick itself and our hosting provider was unsure if it could be recovered. It was in the end, but that’s how we nearly lost 1.95 million database records and ruined Christmas. And yes, you bet we have off-site backups again.

For context, this article discusses a piece of software I work on in my personal time. This software allows users on Discord to easily manage suggestions in their guilds. When I refer to clusters in this post, each cluster represents a single process which is responsible for X percentage of our bots total guilds.
Times are in NZST
Saturday the 23rd, 7:38 PM Link to heading
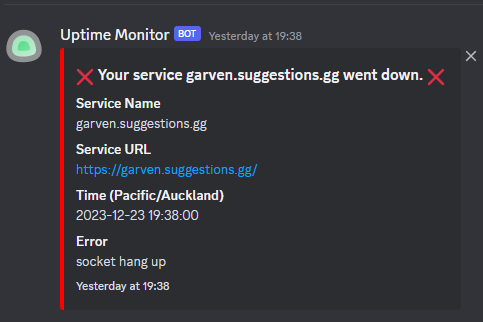
It all started one nice saturday night while playing some Halo with friends, an inconspicuous “Your web service went down” message posted in the internal status channel. A message which given the reporting configuration, occurs regularly enough to where you simply wait for the corresponding “Your service is up” message a minute later. Except a minute later nothing had occurred.
Saturday the 23rd, 7:45 PM Link to heading
A few minutes later, reports of clusters being unavailable starting appearing. Now that’s a cause for concern. They shouldn’t alert unless the internal retry buffer is exceeded. Like clock work, reports of every cluster being down pile in. Not good. But also, this infrastructure should bring itself back up on failure. This was odd sure, but not yet cause for concern.
I put out some comms to our user base that our infrastructure appears to be down and that we are looking into it.
Saturday the 23rd, 8:00 PM Link to heading
Nothing’s changed, time to start taking a look. I’m still in the middle of co-op’ing Halo Reach’s fantastic campaign so investigation is done between deaths.
- Question one: Is it the status service?
- Answer: No. Other services on other boxes haven’t been incorrectly reported.
- Takeaway: It’s not the status service being wrong.
- Question two: Is it plausibly DNS failing to resolve
*.suggestions.ggand thus failing the outbound status request? - Answer: Attempting to navigate to Garven results in a timeout error.
- Takeaway: Not good. Maybe the Docker daemon has I don’t know, decided to give the containers a holiday break?
- Question three: Can we reboot the Docker images via Portainer and all is well?
- Answer: Attempting to connect to Portainer also results in a timeout error.
- Takeaway: Definitely not good.
Now I’m still knee-deep in Halo at this stage and do not have SSH keys setup on my gaming machine so what is the next best thing? VNC. Good ole VNC.
Yet when I attempt to connect, the console is flooded with messages about how the file system is now in a read only state. Shit, that’s really not good.
Saturday the 23rd, 8:04 PM Link to heading
In a last ditch attempt to maybe kick the machine out of whatever state it had gotten itself into, I attempted to power cycle the machine. Little did I know that would be a mistake. Like yes, technically it didn’t end up back in a loop complaining about how the file system was read only. Unfortunately for me however, the message I now received was “No bootable device.”
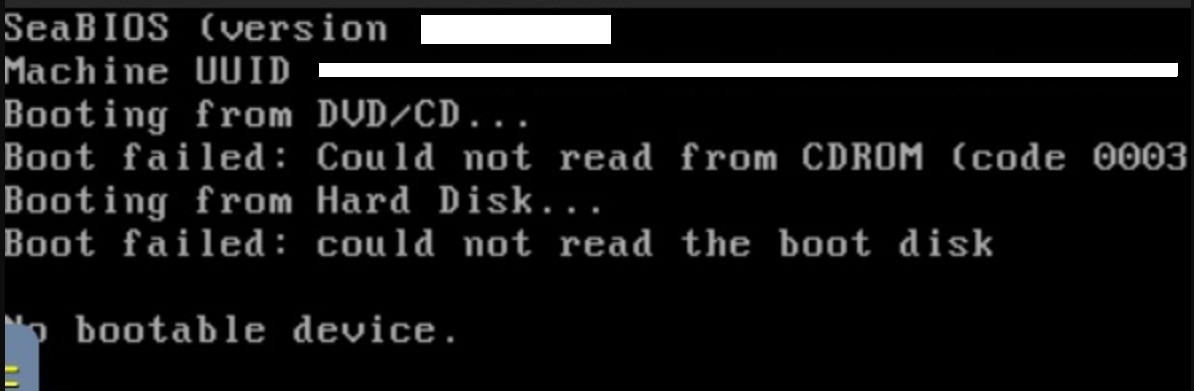
Really not good.
Saturday the 23rd, 8:06 PM Link to heading
However, let’s remain positive, maybe my colleague made some modifications I wasn’t aware of? Let’s ask?

Sadly the response “I havent. Whats up?” does not instill confidence.
Saturday the 23rd, 8:15 PM Link to heading
We reached out to our hosting provider via their support panel and initiated conversations.
Saturday the 23rd, 8:22 PM Link to heading
“Our engineering team is continuing to investigate a node failure that is affecting the listed instance. We have attempted extensive recovery efforts to restore your cloud server to normal operations and have determined additional time and resources will be required with no certainty of a positive outcome. You may deploy a backup or snapshot on a new instance to restore service.”
Oh, dear. And we no longer maintained back-ups of the data since we moved everything on prem a couple of months ago and kinda just haven’t done any major work since then. See the downside of downsizing from nice managed databases as a service and moving to a run it yourself model, is it no longer comes with nice easy “here’s two read replica’s situated on different nodes” and instead comes with “you know you should but haven’t found the motivation yet”.
And yes, while this post does go into nice amounts of detail with a touch of satire. The underlying reasons for its occurrence are of my own making. Downgrading services without having a transition plan in place for how to continue doing automated off site backups is a massive oversight and a textbook thing to call out for. But hey? I hope this serves as a nice little read, maybe a reminder to go backup your own things, or otherwise just see how I manage what could have turned into a worse time.
Saturday the 23rd, 8:28 PM Link to heading
Having looked at what we stored in the database, and what was technically metadata stored in each suggestion within Discord messages themselves I made a call. A call that this would be fine, little of scripting here and there, and we could retroactively rebuild the bits of the database that mattered. Sure we’d lose 800k or so rows of metadata, locale usage and other statistics we used to figure out how to spend what little dev time we had, but that data could be rebuilt over time. What I’m talking about here is the core operating data. The data this little Discord bot that could, needed to function.
Saturday the 23rd, 9:12 PM Link to heading
My colleague signs off for the night. He’s in America after all. I’m left to handle the rest of the night myself.
It’s also at this time I said what I think has to be one of the most kiwi things you can say:
Saturday the 23rd, 9:35 PM Link to heading
It’s around here my mates and I finish the Halo campaign. It’s time to get serious. I boot into my dev machine and starting writing up a disaster recovery plan for the situation at hand.
Saturday the 23rd, 10:07 PM Link to heading
It’s finished, and man do I wish I’d had it before an incident occurred. Note to self; and to readers; make plans for incidents before they happen. It helps.
Anyway, we now have a concrete path forward towards what is required in order to provision a new server if required as well as the parts of the database that can be rebuilt as well as how to rebuild them. At this stage our hosting provider is still attempting to solve the underlying hardware issue, so let’s focus on the plausible data loss.
The next couple of hours are rather boring. I simply worked on a script that would fulfil the requirements of the disaster recovery plan.
Sunday the 24th, 12:09 AM Link to heading
Our internal status tool notifies us that *some of our services have come back online.
Sunday the 24th, 12:13 AM Link to heading
Our hosting provider reaches out to inform us that our instance has recovered and that they are in the process of migrating all affected instances to other hosts to prevent future issues. This may result in a reboot as they are already starting the move to other hosts.
Sunday the 24th, 12:55 AM Link to heading
Our hosting provider reaches out to inform us that this has been completed and regular service should resume.
Sunday the 24th, 1:00 AM Link to heading
After rebooting the machine and massaging a couple services through a finicky reboot (The bot tends to have a slow start due to a few factors currently outside our control, and the bot had restarted a few times during the migration), we marked the issue as resolved and notified our user base that the issue appeared to be all resolved and that associated services should be back online soon.
The takeaways? Link to heading
It’s actually funny, if we didn’t have robust internal reporting I likely wouldn’t have noticed. We had no users reporting issues before we sent out comms regarding the issue to our user base.
It’s also interesting to see how live migrations of entire hosts pan out. For example, I’ve noticed increased DNS lookup failures on the new host as we attempt to rescale to full functionality.
Further, this totally highlighted the importance of regular back-ups as well as having plans in place for when something goes wrong. Even though this is a personal project, that doesn’t mean we are immune to this kind of thing and I’m looking forward to improving going forward. I’d certainly call this some strong motivation.